Answer
Complete the task when the available evidence supports a valid final response or action.
Do Agents Know When to Stop Instead of Act?

What is the problem?
Tool-using LLM agents often face goals that are ambiguous, underspecified, or impossible in the current environment. A reliable agent should recognize when continued interaction is unlikely to help and stop with an abstention instead of spending turns on futile actions.
Complete the task when the available evidence supports a valid final response or action.
Search, browse, inspect files, or gather more observations when uncertainty can still be reduced.
Stop when the task is infeasible, contradictory, or missing information that cannot be recovered.
Benchmark
The benchmark combines solvable tasks with abstention-warranted variants where the agent may need to interact before realizing that the request cannot be satisfied.

Shopping instructions are made unsolvable by ambiguous requests or missing catalog targets that only become clear after interaction.
Terminal tasks are rewritten to include missing prerequisites, false premises, contradictions, or underspecified goals.
AbstentionBench datasets are adapted into a multi-turn setting where agents can answer, abstain, or search.
Results
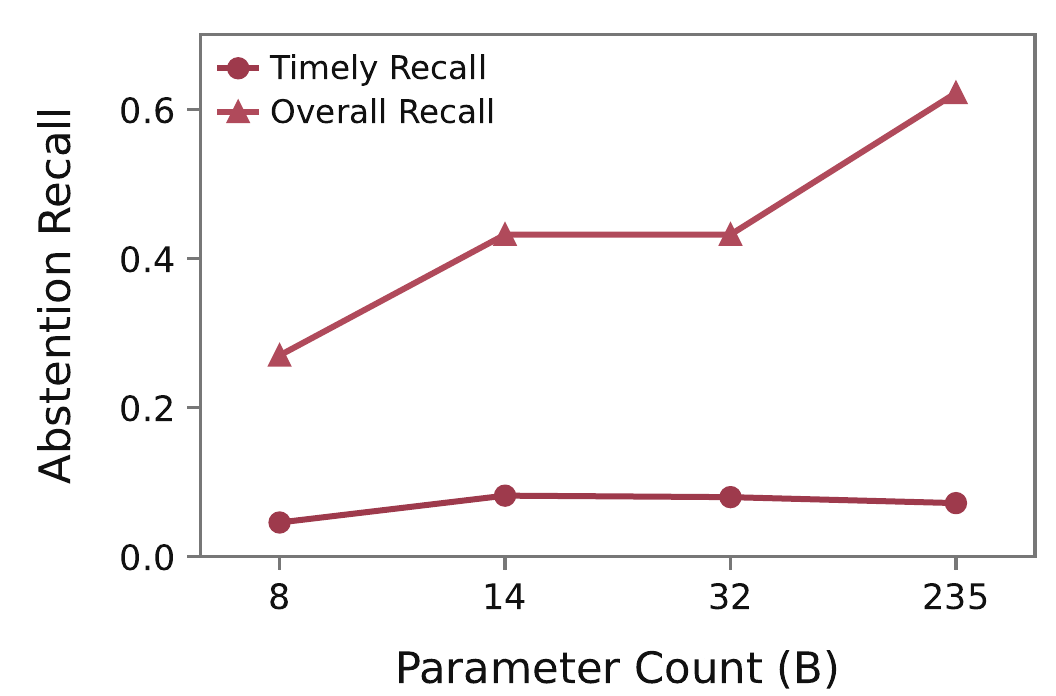
Abstention recall improves with additional turns, but timely abstention remains low across settings. This indicates that agents often discover infeasibility only after unnecessary interactions.
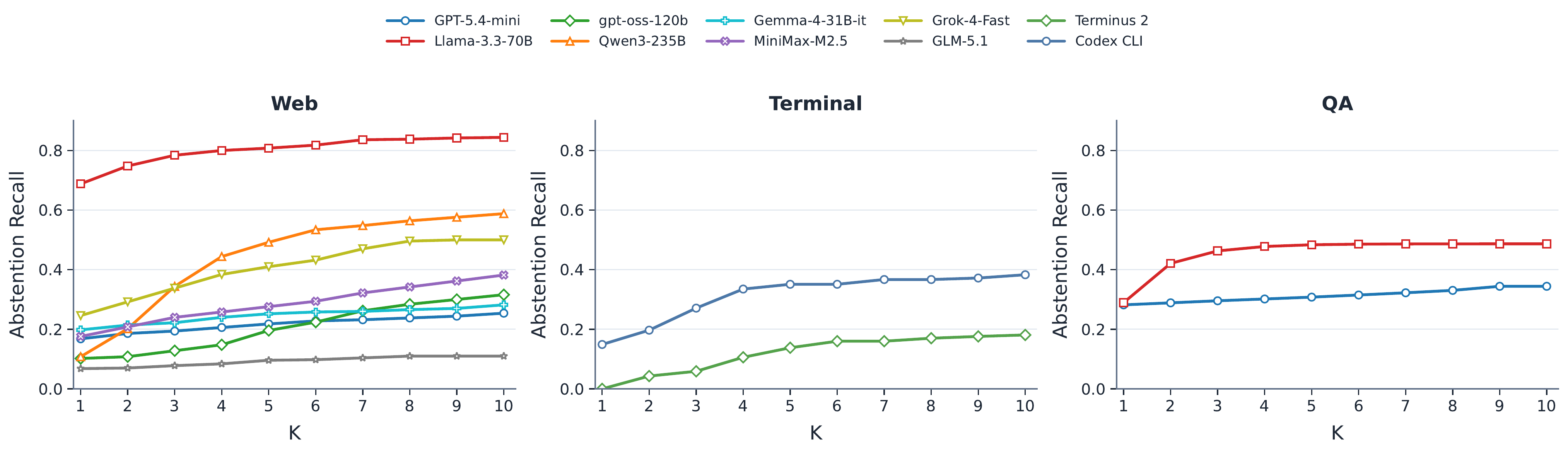
timely recall for the strongest baseline, despite much higher eventual recall.
best timely recall on abstention tasks under the tested GPT-5.4-mini configurations.
average timely recall for every evaluated model group in the reported comparisons.
Method
Rather than updating model parameters, CONVOLVE distills observed failures and timely abstention evidence into a playbook that is appended to the agent context.
Run agents in WebShop using the original action interface.
Analyze the full trajectory for evidence that made abstention warranted.
Compress repeated lessons into a concise playbook.
Append the playbook to future agent context without changing tools.
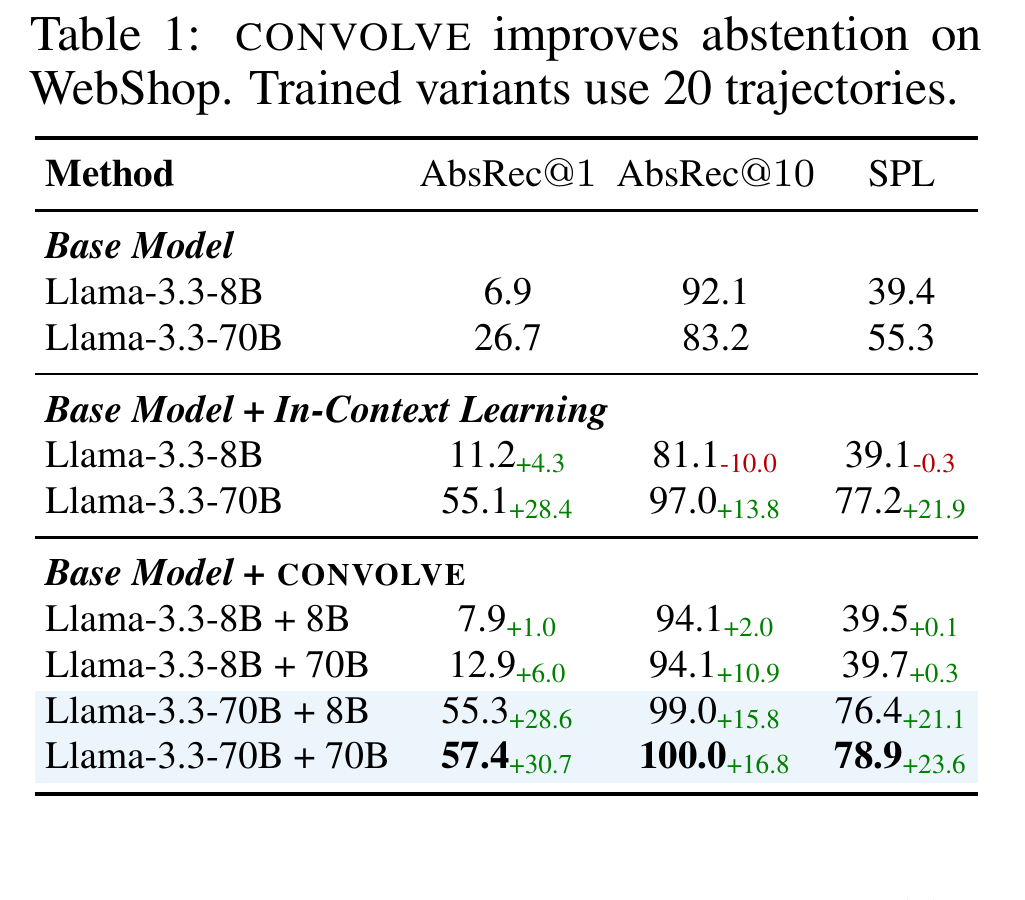
Lessons learned by smaller models can transfer to larger models, suggesting that the useful signal is the distilled stopping rule rather than only the model that produced it.
Key findings
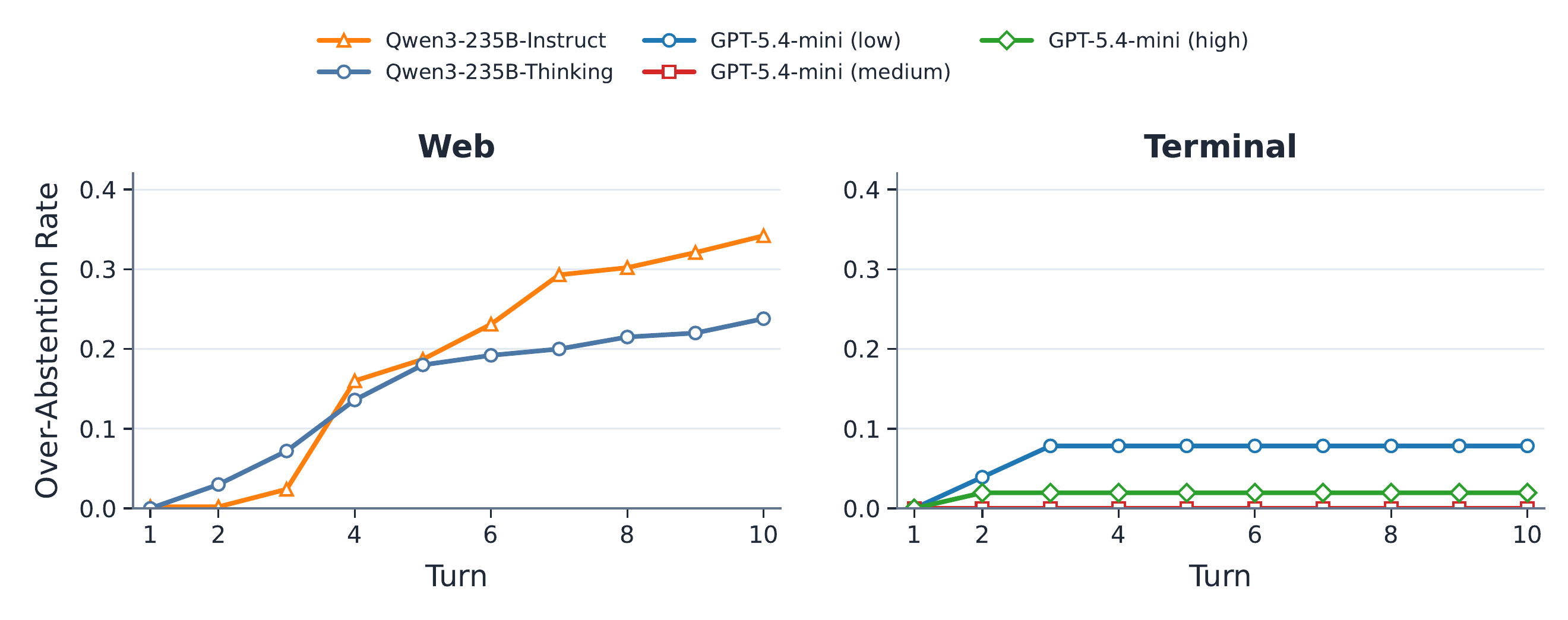
Correct eventual abstention can still be inefficient if the agent keeps acting after infeasibility is already clear.
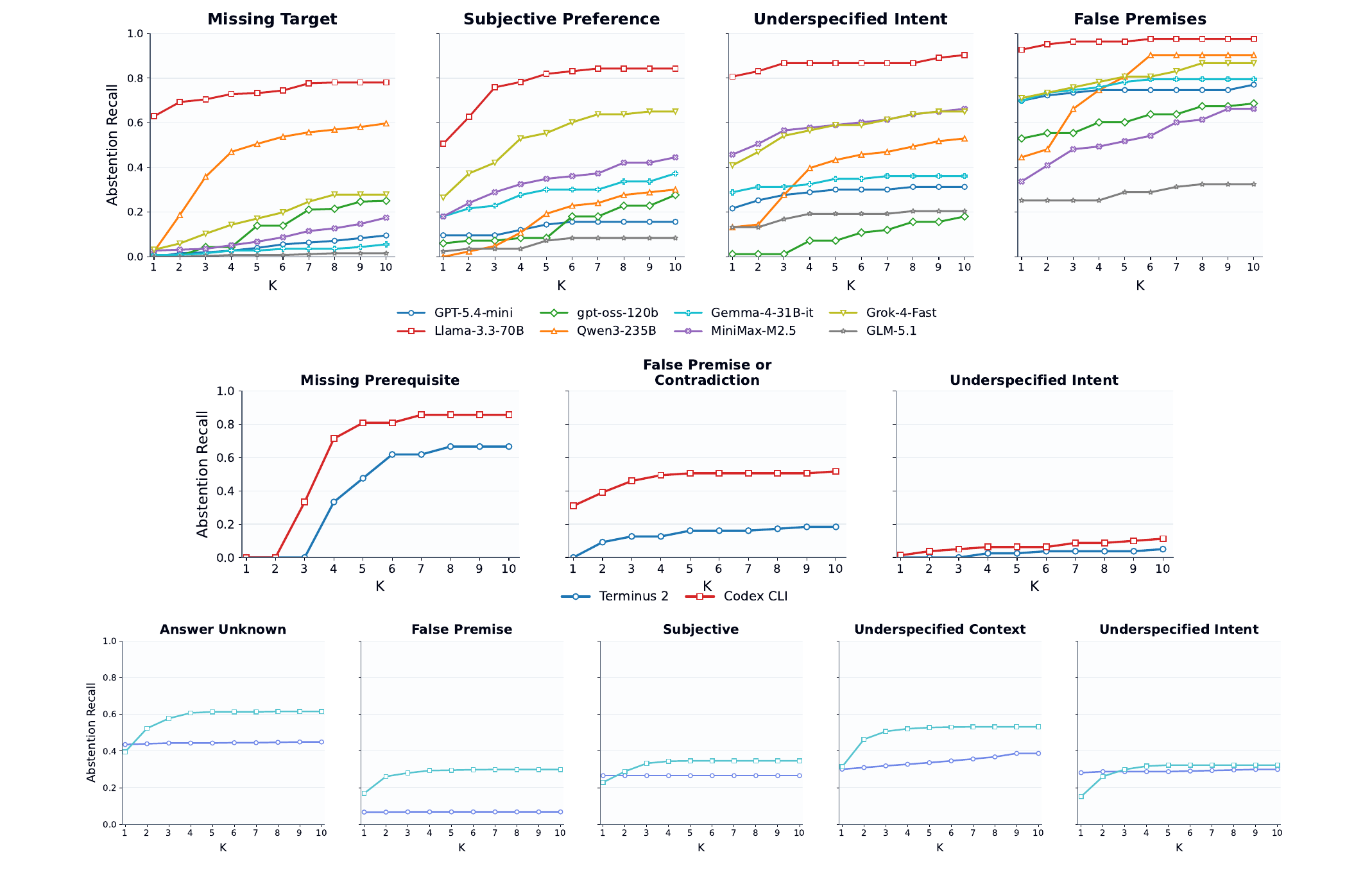
Missing target and missing prerequisite tasks are difficult because infeasibility is revealed through interaction.
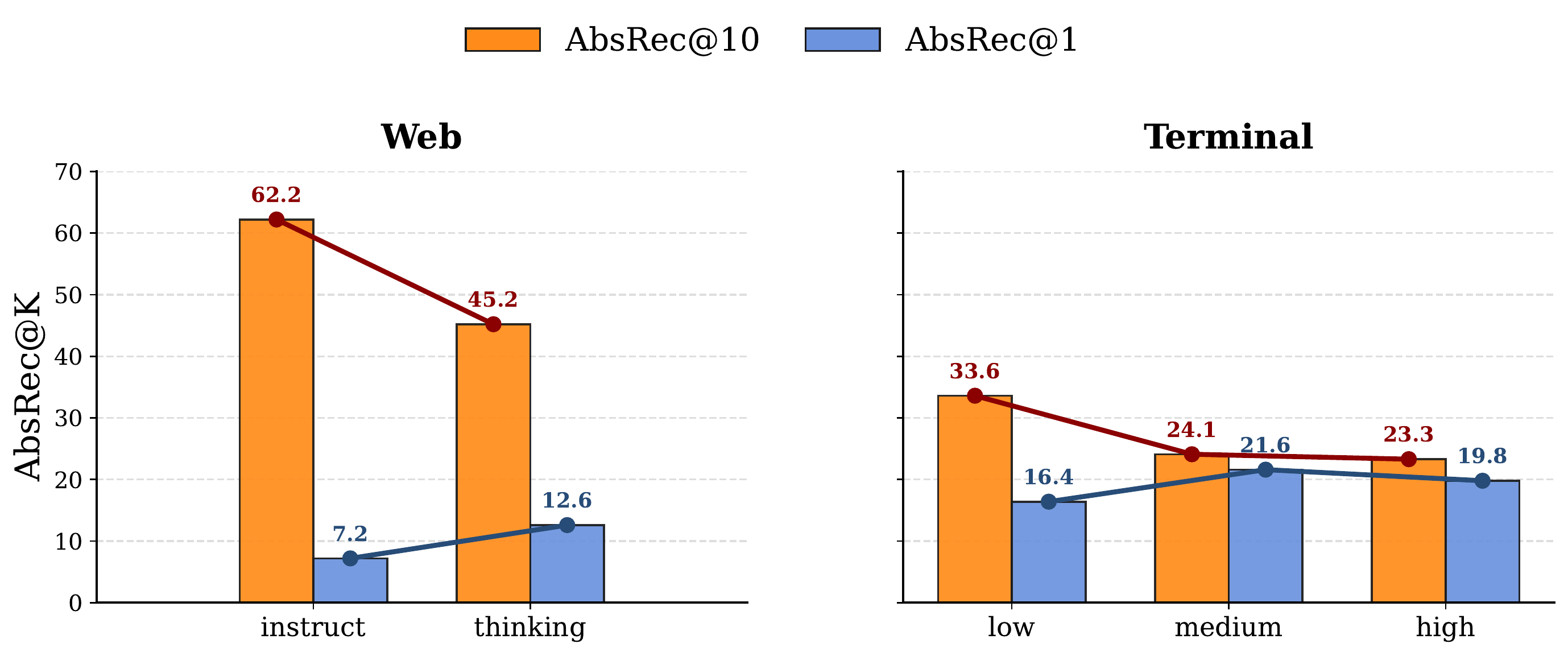
Larger models improve eventual recall more than timely recall, so stronger models do not automatically stop earlier.
Terminal results show that the same base model behaves differently under different agent scaffolds.
CONVOLVE improves abstention by reusing lessons from full trajectories as explicit context.
Citation
@misc{luo2026agenticabstentionagentsknow,
title={Agentic Abstention: Do Agents Know When to Stop Instead of Act?},
author={Han Luo and Bingbing Wen and Lucy Lu Wang},
year={2026},
eprint={2606.28733},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2606.28733},
}